- does not thread comments.
- does not offer RSS comment feeds.
- does not offer any quoting aids.
- enforces severe limitations on markup.
Of course it's possible to converse without either of the above, but it makes for a rather bad reader experience, and that is one of the things the web medium is usually particularly good at, so I'll try to avoid as much of these pains as I can and hopefully improve the reader value of this conversation. Hence this post; I'm trying out my options. In most relevant aspects, this is more of an open mail (after a lead recap) or news posting, adding one thought set to the mix to move one step ahead in a discussion; we are really only discussing things to do and good ways to do them, so far.
And for those who have not followed this discussion thread at Freshblog, where Greg Hill has posted a good tutorial on how to add Del.icio.us tag navigation to a blog (and not only Blogger blog, I might add), here is an executive summary of what has happened so far in the story:
- Greg Hill makes a really spiffy (and very tastefully template integrated, I might add) category navigation system for some of his blogs (Vent, Speccy). It's based on Del.icio.us tags and the Del.icio.us JSON feeds, which enable any web site anywhere to programmatically integrate public tagged bookmarks from Del.icio.us into their sites in any fashion they well please.
- Freshblog (which keeps the temperature on, among other things, blog tech development in general and Blogger blog tech development in particular) reports on Marc Morales having published about how he, borrowing ideas from Greg's implementation, made a Del.icio.us based category sidebar for his blog.
- Greg, further inspired by Marc's efforts, takes the concept a bit further still, and stops by John at Freshblog to show and explain his improvements in a comment to the prior announcement post.
- I stumble by, suggesting Greg would start a tech blog, and then quickly dig into Greg's code to play with a few ideas and get a feel for what I would like to do myself.
- Attention strays when I start researching making some base post tagging tools I miss, before being comfortable with this system. (I take some pride in affording myself to enjoy being a rather lazy person, by way of making support tools.)
- Meanwhile, Greg types up his tutorial (for Freshblog) on not only adding above mentioned category navigation, but also lots of other nifty side effects, such as integrating this tag navigation panel with google searches or previous tags based navigation on a referring blog, and other goodies.
- I play a bit with the code to end up with this blog's tag navigation, and we dive into the above mentioned comment feedback race in the tutorial post, trying to forward the ideas that invariably creep up when creative minds meet around prospects. Worth mentioning is that Stephen of Singpolyma tosses in some idea material and thoughts to the mix as well; this isn't really a dialogue, but more of an eager chattering around a good chunk of geek candy. (We thrive on this kind of thing.)
- This post picks up the ball where we leave off, after another round of Greg's much appreciated query firing. If you made it this far without strying off picking up bits of the story elsewhere, you don't really need to, either; I'm quoting the bits I address. Those I leave (mailing list style) are aspects I have little insight into, but which others would be very welcome to pick up on in posts of their own. I believe you could trackback to Freshblog, or just link back here or to Greg's future tech blog (here's hoping... ;-). Leaving comments is of course very welcome too, but dig in any deeper, and you will probably find it about as lacking as I do.
- My last post suggested splicing in entire posts by means of AJAX into a list of posts you bring forth by choosing a tag might be both somewhat difficult to achieve (albeit doable), and be less robust than relying on time tested hypertext links, in response to some discussion between Greg and Stephen about inlining more post markup than Stephen presently does.
Johan, you don't need to feel ashamed for playing around with this sort of stuff for the fun of it - that is the essence of hackery!
My concern isn't really about the hackery of it, but rather about having a stable and reader friendly environment for "idea exchange" kind of posts, and a somewhat wilder playground for showing off and testing the forefront of browser technology, pushing at the limits of what javascript and modern browsers can do at any one time. I might evolve towards something like that, over time. (But now I'm on far out on a tangent.)
RE: AJAX. I'm only dimly aware of this, but I think anything that makes for a better user experience is good. But I do think there's a lot of value to be had in getting the most out of URLs, referrers etc (and also seeing them in your logs), so it's probably a trade-off between convenience for users and anticipating what they want.
Improving the user experience is always a good thing. Maybe this is just one of these things that needs playing with before one can tell what constitutes improvement, and what just adds additional network traffic and surprising (generally risky business in user interface design) results. Worth considering is also bookmark semantics, and how the user perceives what constitutes the present page. Click a permalink, and the page you get to is good for bookmarking. Unfold an article or a few, and the same might not hold.
Much can be done by pouring in work to address issues like this, if one sets one's mind to it, but it's also always worth questioning your reasoning first. Doing it for fun? Go ahead. If we do it for the user, though, we might actually end up making it harder for real world users even though we meet the demands of our perceived user.
Re: prompt. The earlier version of this did have a "select category" or similar default statement. Maybe that should return in the next release (as a parameter).
Re: Fade Anything Technique. I like! It certainly emphasises that a change has been made. Again, a parameter to select the highlight colour should be passed.
Request for Advice: when doing this kind of scripting, am I better off passing parameters to the js functions (like the height/width info), or is it better code to use global variables (like del_user and anchor)?
I figure that the number of parameters/options will grow, and I'd like some guidelines on making them global variables or passed parameters or something else.
When dealing with a multitude of parameters, all optional, I tend to toss them up into one big parameter object, which is good because you can read the function call and see what each parameter does, without having to peek at the docs for or code of the function itself, unless you want to add something not already there. An example:
write_tags( { header:"Pick a category:", add_link:false,
onclick_cb:goto, tag_name_cb:expand_camelcase } );
function goto( delitag, option )
{
if( delitag && delitag.u )
location = delitag.u;
}
function expand_camelcase( tagname, option )
{
tagname = tagname.replace( /([A-Z0-9])([^A-Z0-9]+)/g, split_words );
return tagname.substr( 1 ).toLowerCase();
}
function split_words( match )
{
return ' ' + match[0];
}My thinking is that the above would write out the normal search field, not write the blogger category link afterward (it might be something the user would want to control herself using some callback invoked when the select box changes focus, for instamce), and that tags would be listed differently in the select box than their names ("BlogTech" being shown as "blog tech", for instance).
Passing the relevant Delicios.tags and the
<option> node to these callbacks, when given, might not be an ideal API, but it seems useful. I suppose I ought to peek through your present code, and toy with it as I did with the other one. It was fun too, after all. :-)You might want to add the option of removing the anchor tag from the list, too; I find it a bit useless, at least in my own blog.
Lastly, here's a thought I had about category integration across blogs: "tag piggybacking". Ie the publisher can select another delicious account (in addition to their own) to augment their tagspace (and hence posts).
Why? Well, when you're just starting out, it might communicate to your readers how you're positioning your content, before you've had a chance to build it up.
Or maybe you'd want to include the tags (or just a subset via anchor tags) of a prominent blogger, work colleague or even a group/shared blog of which you're a member.
It could also be used transiently ie you could have "guest tags" on your blog for a week, to help cross-promote a friend or collaborator. (Perhaps on exchange.)
Certainly. You don't really need to limit the scope to Del.icio.us links being used as category navigation of blogs, even though this serves your above mentioned purposes rather nicely. Instead, I would suggest thinking of this as of syndication in a more generic sense. Consider a JSON bookmark feed another flavour of RSS feed, and the menu opens up additional possibilities.
I'm planning on eventually picking up my feed of CommentBlogging bookmarks with the anchor tags
mycomments+public+eng, to which I (try to) add every blog comment I write (mycomments) in blogs across the world, which I would not mind also publishing in some panel on my blog (public) and are written in English (eng). I also have a swe tag for comments I write in Swedish, my native language, which might end up published on my "real life" blog, in said language. For posts I make in response to incoming feedback to my own blog posts, I only occasionally tag a Del.icio.us bookmark, when I feel that the comment would be worth reading for its contents and by a wide public, then using the tag ownsitecomments. This is scheduled to happen when I have figured out how I want it to look. :-) (Things often stall there for me; I don't do much web design per se, even though I take much pleasure from tweaking something half there to become better or more to my taste.)
I guess this would come in two flavours: fully integrated (their tags are entirely rolled in with yours, producing a virtual "super user"); and demarcated (separate lists, counts, labels etc).
While it may drive traffic away from your site, it could also make your blog richer and more useful hence gain you traffic. And, much like linking/blogrolls etc, what comes around goes around.
If it adds value to your blog and is relevant to your reader base, it's of course a Good (possibly Great) Thing; I won't challenge that. For blogs using the Del.icio.us for categories and/or other navigation, this could even be used to make really good interactively foldable blog rolls, where you could catch a quick glimpse on what goes on in your list of recommended reading without even leaving your own site.
If that was vague, let me clarify, picking up on other plans of mine for this site. I will eventually join the crowd and add some kind of peer links, suggesting other good reading on subjects I address, linking Freshblog, Singpolyma, Browservulsel and a few others too for the mutual benefit of tying in relevant content, knitting a tighter community, and all the other beneficial things about useful blog rolls. In linking to Freshblog, which uses Del.icio.us tags, I could add a little "unfold +" before the name, which might pop up a tree of a few recent post titles, show a tag cloud for Freshblogs' ten or twenty most frequently used tags, or similar, to convey an instant feel of whether the reader would find it worth her while going there for a browse, or perhaps subscription, while at it.
Another thing we can do with both our own and the tags from our syndicated peers, is to provide (link only, or abridged version at best, so far) RSS feeds by category. People coming to my own blog only because they are interested in what development I do on Book Burro could subscribe to the Del.icio.us provided RSS feed covering my bookmark category
ecmanaut+BookBurro, which could be made available with a quick sleight of hand directly from the tags browser, similar to the Del.icio.us link we already have.We have only started tapping the possibilities opened up by JSON feeds yet; there is so much that can be done, and Del.icio.us leverages this even further than any other, more conventional site would. We have much work and play to do here. :-)
(Oh, did I already suggest your starting your own tech blog, by the way, Greg? ;-)


 I thought I'd write something about another small Greasemonkey hack I've made some time ago, which has come to feel like part of the browser itself since I started using it -- it's almost the kind of thing I would consider integrating into the status bar as an extension, by now. What it does? It adds a little tab on the top right which reports the number of links in a page that feature an URL encoded as a query string argument (often used by logger pages that do something you don't care much about and then just redirect to somewhere else). When clicked,
I thought I'd write something about another small Greasemonkey hack I've made some time ago, which has come to feel like part of the browser itself since I started using it -- it's almost the kind of thing I would consider integrating into the status bar as an extension, by now. What it does? It adds a little tab on the top right which reports the number of links in a page that feature an URL encoded as a query string argument (often used by logger pages that do something you don't care much about and then just redirect to somewhere else). When clicked, 

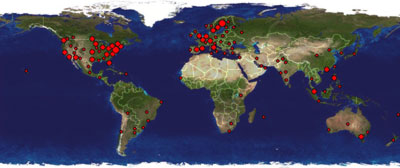
 This will load the big map when hovering the image (and no sooner; we wouldn't want to bother neither visitor nor ClustrMaps with any needless traffic). Not on the first day, though -- ClustrMaps must first generate the first day's traffic picture for you before this comes up anything more than an empty rectangle.
This will load the big map when hovering the image (and no sooner; we wouldn't want to bother neither visitor nor ClustrMaps with any needless traffic). Not on the first day, though -- ClustrMaps must first generate the first day's traffic picture for you before this comes up anything more than an empty rectangle.