Yesterday, after having visited my sister, her husband and two daughters last week-end and become inspired by their DIY photo albums turned books, I too had a peek at Gör din egen bok (.se) (Swedish för "make your own book" -- visit for a fantastically cheesy sample of how it's pronounced). A rather nice web site lowering the bar almost to making it viable to organize and layout a book on a coffee break, if you already have the photos (and/or text you want to go with them).
Not without its kinks; the java photo uploader applet wouldn't manage to convey the bits of my local images from my macbook, and the site click path to the alternative image dropper (via classic form upload) was hidden rather well, until I managed to bookmark it by pasting together attributes scraped from forms with Firebug. (I reckon you might have to glean up the folderId number on your own to get it to work.)
Anyway, I thought I'd set myself up with a book of nostalgia about Spring in Linköping, where I have been living the past decade -- as I'm planning on moving now, relocating to San Francisco, where I have been head hunted by friends of Jesse Andrews' after our run-in with eachother on hacking away at Book Burro. (It has been literally taking me forever to wrap up my CV, ask peers I have worked with in the field of open source and user scripting for references and letters of support for my petition for an O1 extraordinary persons' visa, and I am really looking forward to being through with it.)
Not really having all that many photos taken there though, and with the smallest book format on offer covering a full 20 pages, I asked around friends whether they wanted to chime in a photo or two on the same theme (and location), before figuring that a map would be neat. I'm still big on Google Maps, even though my blog header rotted and hasn't been revised for the Maps v2 upgrade in November, so I fired up Google Earth to see if I couldn't get some nice visuals there.
Not quite satisfied with what I got, I recalled having read about people doing their own Google Maps photo stiching, and with a bit of help from two articles by Pascal Buirey and Charlie Savage and some guesswork, I managed to wrap up a small pike script to do the scraping for me. (The best part of which was the triumphant moment when my mercator projection latitude compensation suddenly came up with the same coordinates as does Google. :-)
It didn't take long to forget that I was really working on picking up some images for a book, but I eventually did have a decent Google Maps fetcher, to pick a w by h tile segment grid around any given latitude/longitude coordinate and zoom level (granted that Google Maps has satellite image data for it), and paste them together into a big png, jpeg or similar image. It ended up somewhere slightly above "crude", yet below handling geocoding, detecting user error and writing mail and I'm kind of glad I stopped there. (Remember to credit image data copyright holders appropriately if you use it!)
The code requires a typical pike 7.6 (or later) installation, and understands the --help command-line argument for a bit of sparse documentation. The linked articles suggest you may end up getting blocked from the tile servers if you choke them and that it is a good idea to cache tiles. All downloaded images get cached in ~/.gmap/ for you, where you may clean up or not as you please. There is no garbage collection of this cache or code to check whether there is a more recent version of a tile at the image server, so you might want to wipe this directory, if it was a long time since you last ran the tool.
Enjoy! I wonder if I'll finish that photo book. :-)
2006-12-30
2006-12-25
UnicodeChecker × dabbrev-expand collision
If you run UnicodeChecker, and, like me, find that it gobbles up the Meta-/ keyword binding for (aqua) emacs' dabbrev-expand funciton, here is how to fix it: in the → System Preferences → Keyboard & Mouse → Keyboard Shortcuts view, add (+) a new binding for the menu title HTML Entities → Unicode (cut and paste to get that arrow right) for All Applications to another keyboard shortcut, say, Command Control 4 (yes, I did :-).
While at it, you might want to bind some of the other fancy things there (the location of these commands is the Services → Unicode menu hidden in each program's own menu) to something you'd remember, on the occasion you want to use something like escaping and unescaping HTML entities, UTF-8 URL encoded strings, IDNA (punycode) host addresses and the like on the fly from the clipboard or a text selection. Here are my present bindings:
While at it, you might want to bind some of the other fancy things there (the location of these commands is the Services → Unicode menu hidden in each program's own menu) to something you'd remember, on the occasion you want to use something like escaping and unescaping HTML entities, UTF-8 URL encoded strings, IDNA (punycode) host addresses and the like on the fly from the clipboard or a text selection. Here are my present bindings:
⌘⌃4 HTML Entities → UnicodeThis feature only works in Cocoa programs though, so you're at a loss in Firefox, for instance. You'll also have to restart the program you want to use the binding in to get it to work with the new binding. (For Finder, this means invoking → Force Quit... and picking Finder.)
⌘⌃⇧4 Unicode → HTML Entities, preserving ASCII (& < > " etc.)
⌘⌃5 Replace Percent Escapes
⌘⌃⇧5 Add Percent Escapes
⌘⌃6 Convert from IDNA Hostname representation
⌘⌃⇧6 Convert to IDNA Hostname representation
2006-12-04
Firebug 1.0 beta gone public
Good news!
The Firebug 1.0 until-recently private beta has gone public beta -- so you can download it now! We have been a select few to track this puppy throughout the last fortnight, probably drowning Joe in feedback, and it's good. It's really good. It's actually the best surgical hack tool I have been using since the age-old C64 and Amiga Action Replay(s) from Datel Electronics in the nineties, and those cheated by using specialized hardware. ;-)
And better still, the release will remain in the open source, no cost, with the Firefox style tri-license MPL/GPL/LGPL combination, having first being slated for going commercial style product with a dedicated developer hired for it, paid in full by the revenue generated from our purchases of the tool. So, in conclusion, Firebug will only get as much attention as donations can pay for, above the spare time available to Joe, recent full-time ambitious startup founder (Parakey software); quoted from the Firebug blog:
I would suggest you download it, try it out for a day or three, depending on how much time you have to devote to turbo-charging your development pace, improved debuggability, at-a-glance electron microscoping of the HTML, CSS and javascript you encounter in the wild as you browse about your daily life, and if you don't find it worth the $25 (or $15 if you're on a tight budget) suggested in Joe's original post, don't pay. Otherwise, please follow my lead and drop in those donations. (The karma boost alone is great! ;-)
Personally, I'm glad that the in excess of 25,000 (yes!) lines of javascript code that in part make up Firebug (there is a lot of UI graphics, and a few thousand lines of xml, xul and css too, of course) are there for us to browse and learn from, not to mention pore through, when there is some curious aspect to how things work, or you wonder about how to do something Firebug does.
The "beta" tag actually means something here; I, for one, initially encountered a suspiciously high firefox freeze frequency (several times a day) when running earlier beta versions on firefox 2, intel mac, in combination with the Stylish extension, but that mostly went away on disabling the latter extension. There are a few bugs and misfeatures left to polish away (in this case possibly not of Firebug's own fault -- it might just as well be a Stylish issue), and our feedback is still useful, hence the beta period.
Joe has unofficially hinted that version 2 will be all about configurability and extendability. Let's make that come a little sooner rather than (indefinitely) later, shall we?
The Firebug 1.0 until-recently private beta has gone public beta -- so you can download it now! We have been a select few to track this puppy throughout the last fortnight, probably drowning Joe in feedback, and it's good. It's really good. It's actually the best surgical hack tool I have been using since the age-old C64 and Amiga Action Replay(s) from Datel Electronics in the nineties, and those cheated by using specialized hardware. ;-)
And better still, the release will remain in the open source, no cost, with the Firefox style tri-license MPL/GPL/LGPL combination, having first being slated for going commercial style product with a dedicated developer hired for it, paid in full by the revenue generated from our purchases of the tool. So, in conclusion, Firebug will only get as much attention as donations can pay for, above the spare time available to Joe, recent full-time ambitious startup founder (Parakey software); quoted from the Firebug blog:
I hope we can raise enough to create a job for someone who loves building web development tools as much as I do. If not, then I would at least like to use the donations to hire an intern to help out for a while.
I would suggest you download it, try it out for a day or three, depending on how much time you have to devote to turbo-charging your development pace, improved debuggability, at-a-glance electron microscoping of the HTML, CSS and javascript you encounter in the wild as you browse about your daily life, and if you don't find it worth the $25 (or $15 if you're on a tight budget) suggested in Joe's original post, don't pay. Otherwise, please follow my lead and drop in those donations. (The karma boost alone is great! ;-)
Personally, I'm glad that the in excess of 25,000 (yes!) lines of javascript code that in part make up Firebug (there is a lot of UI graphics, and a few thousand lines of xml, xul and css too, of course) are there for us to browse and learn from, not to mention pore through, when there is some curious aspect to how things work, or you wonder about how to do something Firebug does.
The "beta" tag actually means something here; I, for one, initially encountered a suspiciously high firefox freeze frequency (several times a day) when running earlier beta versions on firefox 2, intel mac, in combination with the Stylish extension, but that mostly went away on disabling the latter extension. There are a few bugs and misfeatures left to polish away (in this case possibly not of Firebug's own fault -- it might just as well be a Stylish issue), and our feedback is still useful, hence the beta period.
Joe has unofficially hinted that version 2 will be all about configurability and extendability. Let's make that come a little sooner rather than (indefinitely) later, shall we?
2006-11-30
Recent reading
I've been reading a lot lately, and on rather diverse subject matter. My usual reading diet is actually a lot more skewed towards the personal blogs, of a largely nontechnical narratorship. This post will be a little of everything, some out of scope for this blog. It's a bit overdue from when I wrote it, but fortunately it's content that lasts.
- Douglas Crockford (Javascript Architect at Yahoo!, and the most readworthy grandfaherly voice on javascript online) gives a healthy summary of how to write javascript like a native, avoiding the
newkeyword like the plague wherever you can, as it is a tarpit of not-what-you-think-it-is (and a hairy, largely impenetrable mess to debug, when you get it wrong). It's a brief run-down on just the howtos without the full in-depth perspective of the whys and why-nots, and well worth your time, especially if you come from the Java camp (or anywhere else in class land where you lean heavily on thenewkeyword). - If you're really curious about the full view (or the advanced class on the intestines of the language side of javascript / ecmascript), and have an hour to spare, you should seriosly consider watching his three-part Advanced Javascript presentation (continued in part 2 and part 3), covering inheritance, modules, debugging, efficiency and JSON in a more in-depth fashion. Just the bit about how to activate Internet Explorer's easter-eggishly hidden heavy-duty and notably free debug features might be worth your time, actually. By the time I post this, YUI blog has posted it too (it has been floating silently at Yahoo! video for quite a while), where you can find a zipped version of the powerpoint slides, as well.
- A similar, and not quite as technical session on the history and evolution of the DOM and how best to work it (a pragmatic, standards considering run-down, also three-part hour-long presentation) was posted a while ago on the YUI blog, giving me the heads-up about these things being published at all. His javascript writing is in most positive senses encyclopedic, though some of it requires you to know your higher order computer science to get the full picture and value of it. This presentation doesn't, though, and it gives you the often sad and painful story how we got from there to here in web standards.
- To round off, Dean Edwards contributes the last javascript related news in his discovery of a new javascript object orientation device, in the form of compartmentizing inheritance using frames -- how to make your own prototype-extended types without infecting other code, and, by implication and conversely, how to run your own javascript code without polluted prototypes in an environment that is. (Unless someone else picks up the ball on that latter aspect, I might have to do the research and write up an article about it myself, at some later date.)
- A Sunday a few weeks ago, I stumbled upon GNU Lilypond, a freeware music notation program, and got the sudden idea that I wanted to transcribe Tourdion, a French drinking song from around year 1500, that my local choir sung (among other things) on our week-end trip to Budapest a month ago. Anyway, Lilypond, much like TEX, revolves around a plaintext notation for (music) layout, which it then renders into beautiful postscript, PDFs, SVGs or similar. In theory it is prepared for midi output as well, but I don't think that is implemented yet.
It took a few hours, with ample help of its great online documentation, and then I had my score and a great print-quality version (145kb pdf) to keep and to share (and a variant of my own on the tenor voice, which I first misread it as, and kind of grew attached to). The Lilypond notation of the song ended up 4 kilobytes long. - In poring through the Lilypond docs, I also encountered Erik Sandberg's Master's Thesis Separating input language and formatter in GNU Lilypond (Uppsala University, Department of Information Technology March 2006 -- 750 kb pdf), which, among other things, had a great geek's guide to (English) music terminology and notation in its appendices. Excellent; just what I needed to brush up a little on my music vocabulary.
2006-11-12
Google search comics browser
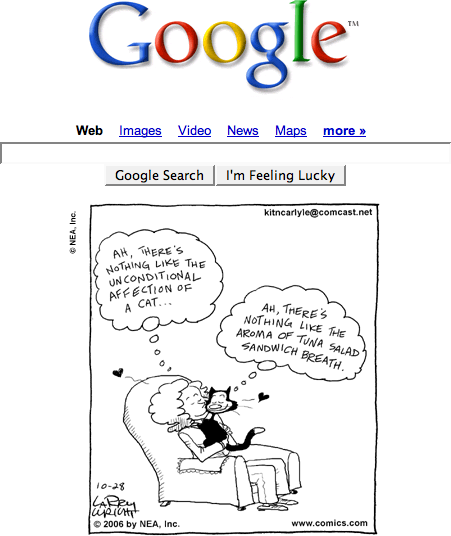 Recall the Google + Dilbert hack I found and refined into an actual minimal comics browser a while ago?
Recall the Google + Dilbert hack I found and refined into an actual minimal comics browser a while ago?Yesterday I figured it might not be too much work tweaking it ever so slightly to cater not just Dilbert strips, but all of the strips published through UnitedMedia at www.comics.com -- about 150 in all (counting the editorials too), including strips like Peanuts, Pearls Before Swine and my recent favourite Kit 'n' Carlyle, pictured on the right.
As it turned out, it wasn't; just the matter of adding a smallish configuration interface, and the code runs just as fine on either of the comics pages of the whole site. Site templates is great tech for web scrapers such as this. All it took was an additional 35 or so lines (to a script weighing in around 200 in total). Install the updated script (userscripts.org page); I opted not to change the name even though it isn't strictly a Dilbert browser any more (still is by default until you reconfigure it to something else, though), since changing script names enables people to have both versions installed at the same time which gives me more hairy bug reports than I quite care for.
The user interface stays the same; click the left third of a comic to read the previous strip, click the right for the next and click the middle portion to go to the comics.com page for the currently seen strip, for sharing with your friends or similar. (Access keys for these links remain P, N and T; Windows users combine those with Alt, Mac users Control.) While there, you will also notice a "Show this comic at Google" link right next to the comic selection box on top that didn't use to be there before.
2006-11-05
MacBook tips
A summaric post about making my recent macbook more habitable; some ouch!s, and their solutions where I've found one.
I also have an oustanding list of issues I'd like to find solutions for, which I'm ticking off as I figure them out. Should you have any ideas or solutions, please tell and I'll migrate them to the end of this list.
- The bottom left key on the keyboard isn't bound to Control!
- Page Up and Page Down are both double-hand, double-key bindings!
- DoubleCommand addresses both issues, letting you bind the fn key to Control and the ⌅ key to fn (so ⌅ plus arrow keys becomes Page Up, Page Down, Home and End). Side note: this does not change the keyboard combinations for the function keys with respect to fn, if you choose to use that combination to access the brightness and volume keys. This is a Good Thing that will hopefully stay the same in future versions of DoubleCommand too (I picked up 1.6.1).
- Most buttons on my Logitech MX500 mouse don't do anything!
- Apparently, all Logitech input devices products have a common driver that lets you configure them to do the most extraordinary things; pick up the Logitech Control Center (lcc211.dmg) download from any product on the site and set it up.
I'm very happy with my own setup, where I set the mouse wheel to button 3 (lets me paste the clipboard in Carbon Emacs), the Back button to ⌘←, Forward to ⌘→ (makes them work in web browsers, iTunes playlists, and with a bit of extra work, Finder), Quick Switch to F11 (default MacOS X binding for [show] "Desktop"), Cruise Up to F9 (default MacOS X binding for [show] "All windows") and Cruise Down to Switch Application.
In Finder, where Back and Forward are by default bound to ⌘[ and ⌘], you can rebind ⌘← and ⌘→ using System Preferences, Keyboard & mouse (the next few tips act out here, so you might as well keep it up). Click the plus button, pick Finder.app, name the Menu title Back and Forward respectively, and feed it the new bindings. You'll have to relaunch Finder to have it recognize the change -- tap ⌥⌘⎋ (that last sign is mac speak for escape, despite not being printed that way on the keyboard) and pick Finder.
To assign the F9/F11 key bindings in Logitech Command Center, you need to temporarily disable those bindings in the Keyboard & mouse preferences (below Dock, Exposé and Dashboard), or those commands will be invoked when you try to bind them to your mouse buttons. Re-check them to turn them on again when you're done. - Tabbing between web page input fields skips check boxes and selection lists!
- There is another setting at the bottom of the Keyboard & mouse menu, "Full keyboard access". You want this set to "All controls" mode.
- How do I get QuickSilver to start automatically?
- In the System Preferences Accounts view, in the Login Items section, you can add new applications that you don't want to have to wake manually every time you start up.
- When connected through wifi networks in the wild, how do I securely tunnel through my home stationary machine?
- This is actually not something I've done in full myself yet, as my stationary machine recently lost name resolution for some reason, but TunnelBlick nicely wraps OpenVPN (just install TunnelBlick and you get both the UI and core application in one installation), and seems like a match in heaven for the task.
- How do I spawn a Pike on this system?
- The quickest and easiest way is probably installing Fink, downloading James Tyson's binary mactel deb:s. (In theory they should be buildable from source as well; I didn't quite have the required time / karma combination to get it flying.) Thanks a ton, James!
- What essential applications do I miss?
- A really good place to find out about good utilities is I use this, especially if you have close friends with a presence there that might be able to help you out or advocate their tools and give good advice. Browsing through your friendship network or people in general and reading user comments about the applications is rather instructive.
I also have an oustanding list of issues I'd like to find solutions for, which I'm ticking off as I figure them out. Should you have any ideas or solutions, please tell and I'll migrate them to the end of this list.
2006-10-19
Me! centric vs You! centric
I was just pointed (by an eagerly link-strewing friend) to Shaun Inman's recent site revamp, and felt compelled to share some thoughts to reflect upon. It is rather good and inventive as art, at the same time as it is indicative of one of the most common mistraits typical for the web, which has been with us since it came and will probably also stay with us indefinitely, or until the rise of the Third Web, a user-centric revolution which at least I hope will eventually see the light of day, eventually. (It will of course get a more fashionable name stylish at the time, and not easily confused with world wars and similar.)
I'm talking about the Me! Me! Me! mentality, the I am the site designer and I know how to use and interpret the design and interaction elements of my site mindset. It is often harmless or a refreshing touch of visual personality branding, but just as often an impediment to visitors, or consumers, in the case of a business.
Changing content-to-background tints and contrasts over time to convey content aging, is a mostly harmless trait, as long as you are aware that you will not really manage to convey that relation by just doing. Any artist is familiar with that -- some may take note of your expression and even place it in the same semantic compartment as you do, but it will either go unnoticed past or end up differently interpreted by most of your audience.
Which is okay -- post time, for those interested, is actually stated in text too, and we can read it at our leisure. Some, who found a really old article of interest, where contrast is prohibitively low, might find it annoying, and occasionally perhaps even close the feedback loop, so Shaun might cap the restyling on the right side of readable (like many designers, he does not discount for his audience not having fine-tuned their display gamma value / contrast settings, the way he and his closer circle have). Or readjust their browser's stylesheet settings, or even find Shaun's own review-with-contrast link.
Breaking behaviour from plaintext or HTML markup in the visitor comment widget, is a more harmful trend that has gained traction in recent months, with Markdown, Textile, and a few other competing WikiML markup variants, popular in some audiences. Typical often-heard arguments for these are that they offer a trade-off between plaintext and complex markups such as HTML or XML, a middle ground providing rich markup without the penalty of a burdensome, difficult markup language such as HTML.
This is unfortunately faux reasoning.
The programming language Pike used to have a manual written in one of these markup flavours, aptly and insightfully named BMML, short for Black Magic Markup Language. On the web, all forms of markup except plaintext (which is what people write with pencils on paper) or HTML, the lingua franca of web markup, which many have invested time in learning to a level they need, and which we can also reasonably assume that browsers will gain increasing levels of support for, for instance via clipboard cut and paste from hypertext enabled tools.
Everything else is black magic markup languages, whether they be called so, or phpBB, Textile, Markdown, TeX, WikiML et cetera. While each and probably all of them can claim readability, they can't claim writability, because users are not hard-wired with their syntaxes and the WYSIWYG coupling is not there; they are expected to already know, or even worse, learn how to adjust to your preferred niche markup language. Why?
And before you knee-jerk that they can just go on writing their plaintext and ignore all about the markup language, can they really? If they want to give you a *hug*, will it come out as a hug? If they convey their moods (like smiles! :-) and flirtation ;-) with emotions, do they come out as moods (like smiles! :) and flirtation ;), as intended? Or perhaps not. Ever tried posting a bit of example code on a blog which treated it as text to style up typographically? Was the example still in a state you could cut and paste and run afterward? “String constans” too? Does it react well to URLs pasted, often sporting radical characters like / and ~?
And even if your user is a highly advanced one, aware of your using an alien markup format, wanting to actually convey his intended text, character for character, and even if you did provide a short summary of the markup rules and/or gave a link to its full documentation, what are the chances that page tells you how to quote a *, or -, or some other BMML cue? The chances of figuring out that within fifteen seconds? Is it * and -? Is it even possible in your BMML flavour of choice?
BMMLs force your audience to jump through the hoops you prefer to jump through yourself. To you (and a subset of your readership, or really commentorship), BMML may improve your speed of typing, or comfort of producing the markup you intend, but to others, it imposes learning a new markup language of very limited application (other sites that jumped the same markup band-wagon).
The today common time investment of having learned one pan-web markup format or using is rendered useless on sites that do not support it, and running your own markup adds a steep learning curve to be able to write properly, for all but your closer circle of friends.
BMMLs are excellent in contexts where you can opt in on them, such as browser extensions offering BMML to HTML conversion of text area contents or comment form content type toggles, offering multiple choice text format options -- as long as the choice is with the user, you are offering improved functionality. When not, it is first and foremost an impediment to using your site or service.
I'm talking about the Me! Me! Me! mentality, the I am the site designer and I know how to use and interpret the design and interaction elements of my site mindset. It is often harmless or a refreshing touch of visual personality branding, but just as often an impediment to visitors, or consumers, in the case of a business.
Changing content-to-background tints and contrasts over time to convey content aging, is a mostly harmless trait, as long as you are aware that you will not really manage to convey that relation by just doing. Any artist is familiar with that -- some may take note of your expression and even place it in the same semantic compartment as you do, but it will either go unnoticed past or end up differently interpreted by most of your audience.
Which is okay -- post time, for those interested, is actually stated in text too, and we can read it at our leisure. Some, who found a really old article of interest, where contrast is prohibitively low, might find it annoying, and occasionally perhaps even close the feedback loop, so Shaun might cap the restyling on the right side of readable (like many designers, he does not discount for his audience not having fine-tuned their display gamma value / contrast settings, the way he and his closer circle have). Or readjust their browser's stylesheet settings, or even find Shaun's own review-with-contrast link.
Breaking behaviour from plaintext or HTML markup in the visitor comment widget, is a more harmful trend that has gained traction in recent months, with Markdown, Textile, and a few other competing WikiML markup variants, popular in some audiences. Typical often-heard arguments for these are that they offer a trade-off between plaintext and complex markups such as HTML or XML, a middle ground providing rich markup without the penalty of a burdensome, difficult markup language such as HTML.
This is unfortunately faux reasoning.
The programming language Pike used to have a manual written in one of these markup flavours, aptly and insightfully named BMML, short for Black Magic Markup Language. On the web, all forms of markup except plaintext (which is what people write with pencils on paper) or HTML, the lingua franca of web markup, which many have invested time in learning to a level they need, and which we can also reasonably assume that browsers will gain increasing levels of support for, for instance via clipboard cut and paste from hypertext enabled tools.
Everything else is black magic markup languages, whether they be called so, or phpBB, Textile, Markdown, TeX, WikiML et cetera. While each and probably all of them can claim readability, they can't claim writability, because users are not hard-wired with their syntaxes and the WYSIWYG coupling is not there; they are expected to already know, or even worse, learn how to adjust to your preferred niche markup language. Why?
And before you knee-jerk that they can just go on writing their plaintext and ignore all about the markup language, can they really? If they want to give you a *hug*, will it come out as a hug? If they convey their moods (like smiles! :-) and flirtation ;-) with emotions, do they come out as moods (like smiles! :
And even if your user is a highly advanced one, aware of your using an alien markup format, wanting to actually convey his intended text, character for character, and even if you did provide a short summary of the markup rules and/or gave a link to its full documentation, what are the chances that page tells you how to quote a *, or -, or some other BMML cue? The chances of figuring out that within fifteen seconds? Is it * and -? Is it even possible in your BMML flavour of choice?
BMMLs force your audience to jump through the hoops you prefer to jump through yourself. To you (and a subset of your readership, or really commentorship), BMML may improve your speed of typing, or comfort of producing the markup you intend, but to others, it imposes learning a new markup language of very limited application (other sites that jumped the same markup band-wagon).
The today common time investment of having learned one pan-web markup format or using is rendered useless on sites that do not support it, and running your own markup adds a steep learning curve to be able to write properly, for all but your closer circle of friends.
BMMLs are excellent in contexts where you can opt in on them, such as browser extensions offering BMML to HTML conversion of text area contents or comment form content type toggles, offering multiple choice text format options -- as long as the choice is with the user, you are offering improved functionality. When not, it is first and foremost an impediment to using your site or service.
2006-10-07
Autobookmark: another day, another bugfix
Don't install a version 1.0 product! ;-)
Anyway, yesterday's automated "oh, where did I trail off reading this comic last time?" bookmarker user script was naïvely flawed, in considering typical strip 99:s more recent than strip 100:s (you know; the ol'e classic "9 is less than 1!" bug).
Just reinstall if, if you were early to the game, and you'll also be rewarded with another feature I threw in for kicks, to get to forget which comics I try to keep track of. I figured that now that I outsourced keeping track of where, why not do away with which, too; the script knows both, after all.
Thus the "Next comic" link that shows up when the "Last read" pointer is the strip you are presently reading anyway -- it will just pick the next comic in the sequence you taught it how far you have read. And if you tried out some comic you don't want to keep in the list, you'll have to remove it by hand, for now; head to about:config, type "read bookmark" in the Filter field, and you will see a row named "greasemonkey.scriptvals.http://www.lysator.liu.se/~jhs/userscript/Automatic last read bookmark.bookmarks" which you can modify to your heart's content (it also defines the comic order). In case you edit it in a way that breaks the script, you can always reset it to read ({}) meaning the empty set.
It's not unlikely I'll eventually release another version making it less messy adding new comics to it, when I come up with a better user interface. That's really one of the main issues with user scripts; they don't help you overly much making comfy, good and stylish user interfaces.
Anyway, yesterday's automated "oh, where did I trail off reading this comic last time?" bookmarker user script was naïvely flawed, in considering typical strip 99:s more recent than strip 100:s (you know; the ol'e classic "9 is less than 1!" bug).
Just reinstall if, if you were early to the game, and you'll also be rewarded with another feature I threw in for kicks, to get to forget which comics I try to keep track of. I figured that now that I outsourced keeping track of where, why not do away with which, too; the script knows both, after all.
Thus the "Next comic" link that shows up when the "Last read" pointer is the strip you are presently reading anyway -- it will just pick the next comic in the sequence you taught it how far you have read. And if you tried out some comic you don't want to keep in the list, you'll have to remove it by hand, for now; head to about:config, type "read bookmark" in the Filter field, and you will see a row named "greasemonkey.scriptvals.http://www.lysator.liu.se/~jhs/userscript/Automatic last read bookmark.bookmarks" which you can modify to your heart's content (it also defines the comic order). In case you edit it in a way that breaks the script, you can always reset it to read ({}) meaning the empty set.
It's not unlikely I'll eventually release another version making it less messy adding new comics to it, when I come up with a better user interface. That's really one of the main issues with user scripts; they don't help you overly much making comfy, good and stylish user interfaces.
2006-10-05
Automatic last read bookmark
Today I crafted a user script I have been missing ever since way before there were any user script capable browsers. A bookmark that remembers my progress through an archive (of comics, typically) I plow through, a few pages at a time, in random bursts, often weeks, months or years apart, without my doing any of the book-keeping, remembering or similar. A bookmark that follows me where I go, keep track of what I read last time and suggest I pick up where I was there, whenever I return to the site.
So let me present the Automatic last read bookmark (direct install link) user script, which does just that. It's predefined to hook in only on megatokyo.com, sinfest.net and qwantz.com, since those are where I always both seem to lose track and eventually return to pick up again, and since all three sites are in the fine habit of keeping a complete archive you can browse, but the script works just as well for many other sites, too, and not just comics either.
To add a new automatic bookmark for some site, just add the domain you want it to run at using Greasemonkey's Tools -> Manage User Scripts dialog for the script and add it among the include links following the pattern. Some minor meddling, that I don't mind overly much doing once for each additional site I want to bookmark.
How it works, once there?
Well, say I go to Qwantz. It's my first time there, so I don't have a [Last read] bookmark. Everything looks just as usual. Today's strip featured at the root page is number 858, but with the root page not being a permalink (it won't necessarily hold the same strip tomorrow), no bookmark is made.
Let's say I go to the Archive, and visit the first strip, from February 1st 2003. Now, the script will silently file a bookmark for this page -- since it found a number in the URL ("/index.pl?comic=1"). Head back to the root page, and you will get a sticky [Last read] link in the top left corner of the page, pointing there. For every page you visit on the site matching the same URL pattern and where the number is greater than your last bookmark, the bookmark is silently updated, and you will be suggested to pick up from there on your next visit.
The script indexes your bookmarks by site and can keep track of however many sites you want it to. And on sites like these, where there is a single numeric straight id embedded in the URL, it will warn you if you happen to bypass any number or numbers, rather than just silently warping the bookmark forward in the sequence.
One final feature: you can always reset the bookmark to some earlier page manually, if you like; just head to where you want it and invoke the Tools -> User Script Commands -> Set last read bookmark to this page menu option. Enjoy!
So let me present the Automatic last read bookmark (direct install link) user script, which does just that. It's predefined to hook in only on megatokyo.com, sinfest.net and qwantz.com, since those are where I always both seem to lose track and eventually return to pick up again, and since all three sites are in the fine habit of keeping a complete archive you can browse, but the script works just as well for many other sites, too, and not just comics either.
To add a new automatic bookmark for some site, just add the domain you want it to run at using Greasemonkey's Tools -> Manage User Scripts dialog for the script and add it among the include links following the pattern. Some minor meddling, that I don't mind overly much doing once for each additional site I want to bookmark.
How it works, once there?
Well, say I go to Qwantz. It's my first time there, so I don't have a [Last read] bookmark. Everything looks just as usual. Today's strip featured at the root page is number 858, but with the root page not being a permalink (it won't necessarily hold the same strip tomorrow), no bookmark is made.
Let's say I go to the Archive, and visit the first strip, from February 1st 2003. Now, the script will silently file a bookmark for this page -- since it found a number in the URL ("/index.pl?comic=1"). Head back to the root page, and you will get a sticky [Last read] link in the top left corner of the page, pointing there. For every page you visit on the site matching the same URL pattern and where the number is greater than your last bookmark, the bookmark is silently updated, and you will be suggested to pick up from there on your next visit.
The script indexes your bookmarks by site and can keep track of however many sites you want it to. And on sites like these, where there is a single numeric straight id embedded in the URL, it will warn you if you happen to bypass any number or numbers, rather than just silently warping the bookmark forward in the sequence.
One final feature: you can always reset the bookmark to some earlier page manually, if you like; just head to where you want it and invoke the Tools -> User Script Commands -> Set last read bookmark to this page menu option. Enjoy!
2006-09-18
RegExp peculiarities and pitfalls
I've received my copy of JavaScript: The Definitive Guide, 5th edition now, and been reading up on things. As expected, it's good. It's really good. And it's been ages since I read much of this, and much of what I pick up this time around I think I must have missed in prior editions, perhaps for no longer being on the same (lower) knowledge level as I used to be (back in the nineties, when I, too, considered javascript a toy language not worth learning in depth).
Anyway, figuring my refresher might refresh or bring useful news to the attention of others, too, I thought I'd share some aha! moments of "Ooh, that's useful!" or "Ouch, that's dangerous!" (The latter probably explaining some rather weird, very difficult to find and work around bugs I've met in my day.)
First things first. The basics: the RegExp
A much better solution is of course to craft a character class which does match any character. My first thought,
Next up, a reminder of what the "multiline" RegExp flag (
Finally, the RegExp flag "global" (
And here comes the pitfall. In order to be able to match later occurrences of a match on the same string when called repeatedly, the RegExp object's
This probably rarely bites people who write wasteful code that never reuses previously instantiated objects. If you do choose to keep a regexp object around, though, it's easy to miss that it carries around stateful baggage from prior uses, and needs to be handled with care. I'll be sure to guard my methods that take RegExp parameters better from this kind of very hard to find bugs that might remain undetected too, for the sheer obscurity of it. Debug printouts (
A contrived example, I agree, especially given that you wouldn't haphazardly throw in a global flag to test for something like this, but to add to confusion, these bugs tend to occur somewhere in the badlands between programmer A and programmer B, one of which typically wrote his code in popular javascript library C and suddenly the clash comes into play.
The cases where I believe I have run into bug due to this easy-to-miss fringe case is with really freaky huge regular expressions (kept cached) to parse out data that once in a while could choose to terminate early (before having iterated through the full match set, where
So be sure to respect the global flag, and whenever you use the
It's in good functional style never to perform destructive operations on passed parameters (unless your method is all about destructive modification, such as to populate some passed object with data), and it's very easy to forget that using a RegExp for some testing and matching is one of these destructive operations. Wear that seat-belt, especially if you ever publicize or otherwise share your code with others. You, and many others, will be glad you did, all those times where horribly weird errors didn't occur and horribly useless bug reports didn't get filed. Thanks.
But you won't ever be given treats for your consideration. Here, have a hug from me, instead. I'll love you for it, anyway, and isn't that something too? ;-)
Anyway, figuring my refresher might refresh or bring useful news to the attention of others, too, I thought I'd share some aha! moments of "Ooh, that's useful!" or "Ouch, that's dangerous!" (The latter probably explaining some rather weird, very difficult to find and work around bugs I've met in my day.)
First things first. The basics: the RegExp
. (literal /./), doesn't match newline (generalized in the Unicode sense) characters. This wasn't much news to me, though it's something I have once in a while kludged around where speed is not of the essence, by starting out with replacing most culprits in the match string with normal space prior to applying the regexp, i e (and this too most likely misses a few cases in above-latin-1-land) mystring = mystring.replace( /[\r\n]+/, ' ' ); -- so I can then write match patterns where . matches any character.A much better solution is of course to craft a character class which does match any character. My first thought,
[^], turned out to play well with Mozilla 1.5 but pretty much nowhere else (it probably breaks the ecmascript standard, though I didn't bother taking the time to verify), and my second try, [\s\S] (any whitespace or non-whitespace character), works nicely in Mozilla, Opera (9) and Internet Explorer (6) alike. Your browser, identifying itself as "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)", handles it too.Next up, a reminder of what the "multiline" RegExp flag (
/^foo$/m) does: it widens the semantics of ^ and $ to match not just start and end of string, but start and end of line too. Only that. Nothing else. (Really!)Finally, the RegExp flag "global" (
/lotsaplaces/g). Here be dragons! But first, a useful feature I wasn't aware of: String.prototype.match, when fed a global-match RegExp, returns an Array with all match occurrences in the string (the full match; no match groups). I have usually been messing with loops around RegExp.prototype.exec to get hold of these before, often for very little reason, figuring mystring.match( regexp ) and regexp.exec( mystring ) were doing identically the same. In the case of global RegExps, they don't; exec always gives you all the match groups, one match per call.And here comes the pitfall. In order to be able to match later occurrences of a match on the same string when called repeatedly, the RegExp object's
lastIndex property gets set to the next character position after the last found match (or zero, when no match was found). The next search, using that very same RegExp object, which remembers how far into the string it should start looking, will start looking there, on whatever string fed to it. Unless you start out by zeroing lastIndex before performing your exec() (or test()) call.This probably rarely bites people who write wasteful code that never reuses previously instantiated objects. If you do choose to keep a regexp object around, though, it's easy to miss that it carries around stateful baggage from prior uses, and needs to be handled with care. I'll be sure to guard my methods that take RegExp parameters better from this kind of very hard to find bugs that might remain undetected too, for the sheer obscurity of it. Debug printouts (
RegExp.prototype.toSource()) of the RegExp object doesn't mention the state of the lastIndex property, and if your test() for occurrences of the character "h" in "hi ho, hi ho, it's off to work we go" returns false once every five calls, it's likely to go unnoticed, or, at best, yield a bug report stating that "sometimes, something doesn't work here".A contrived example, I agree, especially given that you wouldn't haphazardly throw in a global flag to test for something like this, but to add to confusion, these bugs tend to occur somewhere in the badlands between programmer A and programmer B, one of which typically wrote his code in popular javascript library C and suddenly the clash comes into play.
The cases where I believe I have run into bug due to this easy-to-miss fringe case is with really freaky huge regular expressions (kept cached) to parse out data that once in a while could choose to terminate early (before having iterated through the full match set, where
lastIndex would be reset to zero automatically), and leave a non-pristine RegExp with state baggage from last run, missing early matches on the next run, on some other data set.So be sure to respect the global flag, and whenever you use the
test() or exec() methods on a RegExp object Not Instantiated Here (evil twin of the Not Invented Here rule), either start off zeroing its lastIndex property, or better still (so you don't wreck state for your caller) start off making a copy the passed RegExp for your own use -- new RegExp( passed_regexp ) (and don't forget the "new" keyword, or you get the same object back), which gets its own zeroed lastIndex.It's in good functional style never to perform destructive operations on passed parameters (unless your method is all about destructive modification, such as to populate some passed object with data), and it's very easy to forget that using a RegExp for some testing and matching is one of these destructive operations. Wear that seat-belt, especially if you ever publicize or otherwise share your code with others. You, and many others, will be glad you did, all those times where horribly weird errors didn't occur and horribly useless bug reports didn't get filed. Thanks.
But you won't ever be given treats for your consideration. Here, have a hug from me, instead. I'll love you for it, anyway, and isn't that something too? ;-)
2006-09-01
Blogger beta templates
I got curious about the Blogger Beta templates and had a peek of my own. They still merit the "Beta" tag, but a lot is already in a working or partially working state. Maybe even most of it, though I sense a still partially non-exposed aspect of their widget system, which would be a lot of fun to play with once released. Conceptually, it's a system similar to RXML or CFML; a markup language for server-side composition rendered dynamically with every page-load. Blogger's new markup language seems to be called GML (Google Markup Language, most likely), judging by the namespace markers.
It's probably similar to other blog platform widget markup languages, but I do not have that frame of reference. A few years as a developer of and technical writer on Roxen WebServer yielded me some high profile knowledge on the making of template languages, though, and there are a few perls to pick in Blogger's new template engine.
Some concept docs are already in place about the page elements; <b:section> tags in your template mark places where widgets can be placed in the page flow and <b:widget> tags (placable inside the former) define the part of each widget that gets rendered into the web page (server side) on the spot where the tag was encountered in the template. (Presently the pageType attribute doesn't seem to be handled as documented -- at least any I enter are swallowed, ignored and wiped away the next time I load the template.)
To me, what we see so far is about a quarter of to maybe half of what constitutes this widget engine. Each widget also has a configuration view, storage backend and data object model, all tying into one another, and the rendered page as a whole has a document object model. We don't have docs about or access to either yet, but I'd love to eventually see information about this Blogger DOM. With luck that is what we will see in the detailed widget tags docs, once they show up. With even more luck, we will eventually also see and be able to make and share widgets of our own, complete with configuration views and server-side persisted data. (Here's hoping, anyway.)
This post will enter even more speculative grounds from here, as I'm just theorizing around my findings about the mechanics of this template system now -- there is little trial-and-error empirical evidence backing it, so expect flaws where my intuition was not compatible with those of the Blogger template engineers'. All tags mentioned may (and mostly do) contain additional tags, unless specified otherwise. I'm addressing a programmer audience below, assuming some familiarity with variables, flow control and XML markup.
It's probably similar to other blog platform widget markup languages, but I do not have that frame of reference. A few years as a developer of and technical writer on Roxen WebServer yielded me some high profile knowledge on the making of template languages, though, and there are a few perls to pick in Blogger's new template engine.
Some concept docs are already in place about the page elements; <b:section> tags in your template mark places where widgets can be placed in the page flow and <b:widget> tags (placable inside the former) define the part of each widget that gets rendered into the web page (server side) on the spot where the tag was encountered in the template. (Presently the pageType attribute doesn't seem to be handled as documented -- at least any I enter are swallowed, ignored and wiped away the next time I load the template.)
To me, what we see so far is about a quarter of to maybe half of what constitutes this widget engine. Each widget also has a configuration view, storage backend and data object model, all tying into one another, and the rendered page as a whole has a document object model. We don't have docs about or access to either yet, but I'd love to eventually see information about this Blogger DOM. With luck that is what we will see in the detailed widget tags docs, once they show up. With even more luck, we will eventually also see and be able to make and share widgets of our own, complete with configuration views and server-side persisted data. (Here's hoping, anyway.)
This post will enter even more speculative grounds from here, as I'm just theorizing around my findings about the mechanics of this template system now -- there is little trial-and-error empirical evidence backing it, so expect flaws where my intuition was not compatible with those of the Blogger template engineers'. All tags mentioned may (and mostly do) contain additional tags, unless specified otherwise. I'm addressing a programmer audience below, assuming some familiarity with variables, flow control and XML markup.
Data types
The data widgets handle comes in several varieties. First, there are the scalars -- strings, maybe (or at least conceptually) integers (perhaps just string-to-integer coercion rules), enums (pick-a-string-from-a-given-list) and booleans (the enum "true" / "false"). Second, there are the compound types; objects and collections of objects. All data coexist in a server-side object model operated on by the new Blogger tags and custom-namespace expr:* attributes that you may use with regular HTML tags too.data: tags
Scalars are available for insertion directly into the document by way of the tags in the data:* namespace. Just name the scalar and wrap it in a tag and its value gets injected into the document, i e <data:blog.pageType/> would yield index for the root (or a label lookup) page, archive when on an archive page and item for a post page. The complete layout of the Blogger DOM is not addressed by this post, but keen researchers are encouraged to link back to this post from their references and show up in backlinks here, for the benefit of all readers (including myself :-), until Blogger takes its time to publish one.expr: attributes
As XML documents don't allow tags inside tag attributes, the expr:* attribute namespace, which you can use with any HTML tag, lets you expand data there too in a similar fashion. If, say, you wanted to expand the data:blog.homepageUrl value into the href attribute of a link tag, you would write that as <a expr:href='data:blog.homepageUrl'> -- just tuck on the attribute name you would have used after the expr: prefix. If what you wanted in the attribute was a combination of a variable and something else, expr:* attributes allow a certain amount of flexibility via string concatenation, such as expr:href='data:post.url + "#comment-" + data:comment.id' (note the different types of quotation used; apostrophes to encase the full XML attribute and quotation marks to hold the string literal).The rest of the tags
- <b:includable>
- Moving on and in another level from the <b:widget> tag, we see one or more <b:includable> tags. You might compare these with the <xsl:template> rules of an XSLT template; they may invoke one another, passing along parameters (one parameter, anyway).
- id (mandatory)
- This is the (widget unique) name, by which the template rule is invoked from elsewhere. Every widget tag has an includable with an id attribute "main", which is what gets run when the widget is rendered into HTML form.
- for (optional)
- The for attribute names the incoming parameter for the variable scope visible within the includable, overshadowing data under the same name in the caller's scope. Not all includables accept parameters. In the absence of a for parameter (when a variable was passed), the name defaults to data. The type of the parameter passed to the main template is given by the type attribute of the <b:widget> tag, and its exposed object model varies accordingly.
- <b:include>
- This tag invokes another (or possibly the same, if recursion is supported) includable within the same widget definition.
- name (mandatory)
- The name parameter corresponds to the id parameter of the <b:includable> you wish to invoke.
- data (optional)
- The data parameter selects what data you wish to pass along to the <b:includable> you are invoking (as named in the current variable scope), if any.
- <b:loop>
- This construct is the iteration clause, that lets you loop over a collection, repeatedly applying the contained markup block once for every item in the collection.
- values (mandatory)
- This attribute names the collection to iterate over. For instance, you could loop over every label using data:labels for a type="Label" widget.
- var (mandatory)
- In the scope inside of this tag, this names the variable holding the object for the present loop iteration. It is the logical equivalent of the <b:includable> tag's for attribute. In other words, if we supply a var="comment" parameter and the objects in the collection have a body property, we can print that using <data:comment.body/>.
- <b:if>
- This tag is the conditional, picking one of two different outputs. In the absence of an <b:else/> branch, it either outputs its full contents or nothing at all, depending on the conditional. With an <b:else/> tag present inside, it picks the part before or afterwards depending on the result of the test.
- cond (mandatory)
- This attribute lists the condition to test on. It may be just a variable name (i e cond='data:post.allowComments', to test a boolean's truth value), or an expression, such as cond='data:blog.pageType == "item"' (again note the use of alternating types of quotation; one for the XML attribute encasing, another for the string literal). These expressions may use the operators ==, for testing for equality and != for testing for non-equality.
- <b:else/>
- This tag may not have any content, and it may only appear inside an <b:if> tag. It splits the contents of its parent in two, the first being the branch to execute when the conditional was met, and the second when it was not.
2006-08-20
The AdBlock random serial killer mystery
I think for the past year or even years, I have been encountering strange site breakage I've always, more or less subconsciously, incorrectly attributed to site owners. Random broken pictures here and there, typically in galleries, albums and the like. Rarely but frequently enough to give the slightly "tainted" feeling of browsing around a site kept slightly but not perfectly in trim, or that there was some lacking quality assurance in the site's file upload dialog allowing partial uploads, making faulty data format conversions and / or similar. Perhaps one in every few hundred images broken, and only on IIS sites like those mentioned in my last post. Knowing a bit too much about the web, you can often make up lots of plausible explanations for the kind of breakage you encounter once in a while.
But a few days ago, I encountered a piece of breakage that just wouldn't be explained like that, on a community site where site native functionality had been turned off on one profile. You couldn't use the messaging or commenting functionality there, because it was shut down; dropped from available options. Clicking links leading to the profile would mysteriously blow away the entire frame in a way I couldn't even begin to understand; it was all most unfathomable and I couldn't help suspect my own client side hackery; was there any one of my userscripts that could have been behind all of this?
Checking the DOM of these pages, there were indeed the elements that were gone; they had their nodes but were shut out via a CSS display:none; attribute. Surely I hadn't done anything like that in any of my scripts? Well, apart from that odd hack where I put an onerror handler on a few images injected by myself that would drop the image from display if its URL had gone 404 missing. No, that just wouldn't explain it -- and further on, the problem wouldn't go away with the first Greasemonkey debugging tip to try at any time you suspect something like this: clicking the monkey to turn off all Greasemonkey functionality temporarily and reloading the page. Yep, still the same mysterious dissapearances. So the monkey went back on again.
By a stroke of luck, I finally stumbled on the culprit: AdBlock, and more precisely, a very trigger happy regular expression rule fetched by the Filterset.G updater for trashing ads that, by the sheer length of it, looks like it would be a very specific fit indeed only to trigger very specific match criteria:
/[^a-z\d=+%@](?!\d{5,})(\w*\d+x\d)?\d*(show)?(\w{3,}%20|alligator|avs|barter|blog|box|central|context|crystal|d?html|exchange|external|forum|front|fuse|gen|get|house|hover|http|i?frame|inline|instant|live|main|mspace|net|partner|php|popin|primary|provider|realtext|redir\W.*\W|rotated?|secure|side|smart|sponsor|story|text|view|web) ?_?ads?(v?(bot|brite|broker|bureau|butler|cent(er|ric)|click|client|content|coun(cil|t(er)?)|creative|cycle|data(id)?|engage|entry|er(tis\w+|t(pro)?|ve?r?)|farm|feelgood|force|form|frame(generator)?|gen|gif|groupid|head|ima?ge?|index|info|js|juggler|layer|legend|link|log|man(ager)?|max|mentor(serve)?|meta\.com|mosaic|net|optimi[sz]er|parser|peeps|pic|po(ol|pup|sition)|proof|q\.nextag|re(dire?c?t?|mote|volver)|rom\.net|rotator|sale|script|search|sdk|sfac|size|so(lution|nar|urce)|stream|space|srv|stat.*\.asp|sys|(tag)?track|trix|type|view|vt|x\.nu|zone)) ?s?\d*(status)?\d*(?!\.org)[\W_](?!\w+\.(ac\.|edu)|astra|aware|adurl=|block|login|nl/|sears/|.*(&sbc|\.(wmv|rm)))/
A bit of a mouthful, yes. What it does? Well, summarically, it'll snag anything matching the substring "ad", optionally surrounded by one of a busload of words often denoting ads found across the web(*).
For instance, the strings "-AD" or "{AD" will do. That's incidentally a very common thing to find in GUIDs, which IIS servers like to sprinkle all over their URL space. There are five spots in those 38-byte (or sometimes four in 36, when braces are gone) identifiers that each has a one in 256 chance of triggering a hit, assuming a perfect randomness distribution. Some URLs even have two or more GUIDs in them, increasing chances. I'm a bit surprised it doesn't strike more viciously than it does, but it's probably because the randomness distribution isn't anywhere near perfect.
That regexp ate my friends! Down, boy! Baad regexp! Nooo good regexp cookie for you!
http://f.helgon.net/g/{451/{45167369-C843-4D00-AD38-AB2184AF0008}.jpg
http://photo.lunarstorm.se/large/9C4/{9C495852-AD84-4FE9-BB5F-7DAAD05CFB77}.jpg
The issue has apparently already been reported to the Filterset.G people a year ago, though it was deemed unfixable at the time. I submitted a suggested solution, hoping for it to get fixed upstream; tucking in a leading (or trailing; just as long as it doesn't end up a character range qualifier) dash and opening curly brace fixes this particular GUID symptom.
At large, though, this looks like a regexp that evolved from two strict regexps being laxed and "optimised" into one, for instance, or one with a lot of self repetition being made less self repetitive and overly lax in the same blow.
By the looks of this huge regexp, it wants to find and match whatever matches either "something-ad" or "ad-somethingelse" -- a string matching "ad" with any in a set of known prefixes and/or suffixes known to signify an ad. In regexp land, you formulate this as "(prefix-)ad|ad(-suffix)". This will not get false positives for random words not listed among the given pre/suffixes, such as words like "add" or good the guys like "AdAware", or random GUIDs, whereas it might be set to trigger for "livead", "mainad", "adbroker" or "adcontent" for instance, as listed above.
But what this regexp does instead, is to match for the regexp "(prefix-)?ad(-suffix)?", meaning: match "(prefix-)ad(-suffix)", "(prefix-)ad", "ad(-suffix)" or simply "ad", on its own!
Ouch! Given that we're just interested in whether we hit a culprit or not, suddenly that whole slew of carefully recorded words meant to strengthen the regexp against false positives, doesn't! We might just as well throw them away. They of don't do any harm, of course, except wasting a bit of memory and computrons every time the regexp is used, but they don't do anything good either unfortunately.
And worse: by being there at all, as we're (particularly when working with people who are very skilled artisans at what they do) mostly tempted to assume code is there for a purpose, and one that meets the eye, unless explicitly describing the deeper magics hidden below the surface in a nearby comment, they imply being useful for something. Which wastes mind resources that try to improve on it, figuring that I'll just add this additional word that is a known ad to improve the matcher incrementally. Except here it won't achieve squat!
This is a very frequent cause of debugging-induced madness: trying to improve code that has secretly been broken for who knows how long. It's convention to write code that works, so except when in deep bug hunt mode, we read the surface of the code, rather than digging into that huge mindset which reads the entire code chunk structure, filtering all possible input through it to see what happens to it. Especially with long regexps like this.
This is something to take heed with, and a problem that grows more likely to bite you especially as expressions or nesting and complication levels rise in a chunk of code, whichever language you use. Increased complexity comes at the price of a matching decrease in readability, and before you know it, very intricate and hard to find and solve problems creep all over.
While I've given a rough suggestion of the real problem with the above regexp, I can't do any good job of going over how it should look instead, as the complete regexp lists seventeen consecutive conditions to be met, eleven of which are on/off/zero-to-many toggles and I don't know which combinations of those the regexp has been aiming for meeting in combination.
Most likely, though, picking any random one of them that satisfies the above recipe will immensely strengthen the regexp against false positives, just by giving the already provided word lists meaning again. With luck (and I'd be surprised or sad if this is not so), the Filterset.G maintainers have their regexps version controlled with good checkin comments noting what prompted every change, so they can track back to the commit where the two red culprit question marks in the regexp got added (assuming they were not there from the very beginning) to see which parts were meant to go where in the match. And if they were there from the very beginning, it's just to try mending the situation from here as best you can guess.
I believe this story has many lessons to teach about software engineering, and not only the magics of regexpcrafting. Plus, I finally found and slayed the random serial killer that would wreak havoc in the IIS family photo albums! I'm sure we will all sleep better at night now for it. Or maybe not.
But a few days ago, I encountered a piece of breakage that just wouldn't be explained like that, on a community site where site native functionality had been turned off on one profile. You couldn't use the messaging or commenting functionality there, because it was shut down; dropped from available options. Clicking links leading to the profile would mysteriously blow away the entire frame in a way I couldn't even begin to understand; it was all most unfathomable and I couldn't help suspect my own client side hackery; was there any one of my userscripts that could have been behind all of this?
Checking the DOM of these pages, there were indeed the elements that were gone; they had their nodes but were shut out via a CSS display:none; attribute. Surely I hadn't done anything like that in any of my scripts? Well, apart from that odd hack where I put an onerror handler on a few images injected by myself that would drop the image from display if its URL had gone 404 missing. No, that just wouldn't explain it -- and further on, the problem wouldn't go away with the first Greasemonkey debugging tip to try at any time you suspect something like this: clicking the monkey to turn off all Greasemonkey functionality temporarily and reloading the page. Yep, still the same mysterious dissapearances. So the monkey went back on again.
By a stroke of luck, I finally stumbled on the culprit: AdBlock, and more precisely, a very trigger happy regular expression rule fetched by the Filterset.G updater for trashing ads that, by the sheer length of it, looks like it would be a very specific fit indeed only to trigger very specific match criteria:
/[^a-z\d=+%@]
A bit of a mouthful, yes. What it does? Well, summarically, it'll snag anything matching the substring "ad", optionally surrounded by one of a busload of words often denoting ads found across the web(*).
For instance, the strings "-AD" or "{AD" will do. That's incidentally a very common thing to find in GUIDs, which IIS servers like to sprinkle all over their URL space. There are five spots in those 38-byte (or sometimes four in 36, when braces are gone) identifiers that each has a one in 256 chance of triggering a hit, assuming a perfect randomness distribution. Some URLs even have two or more GUIDs in them, increasing chances. I'm a bit surprised it doesn't strike more viciously than it does, but it's probably because the randomness distribution isn't anywhere near perfect.
That regexp ate my friends! Down, boy! Baad regexp! Nooo good regexp cookie for you!
http://f.helgon.net/
http://photo.lunarstorm.se/
The issue has apparently already been reported to the Filterset.G people a year ago, though it was deemed unfixable at the time. I submitted a suggested solution, hoping for it to get fixed upstream; tucking in a leading (or trailing; just as long as it doesn't end up a character range qualifier) dash and opening curly brace fixes this particular GUID symptom.
At large, though, this looks like a regexp that evolved from two strict regexps being laxed and "optimised" into one, for instance, or one with a lot of self repetition being made less self repetitive and overly lax in the same blow.
By the looks of this huge regexp, it wants to find and match whatever matches either "something-ad" or "ad-somethingelse" -- a string matching "ad" with any in a set of known prefixes and/or suffixes known to signify an ad. In regexp land, you formulate this as "(prefix-)ad|ad(-suffix)". This will not get false positives for random words not listed among the given pre/suffixes, such as words like "add" or good the guys like "AdAware", or random GUIDs, whereas it might be set to trigger for "livead", "mainad", "adbroker" or "adcontent" for instance, as listed above.
But what this regexp does instead, is to match for the regexp "(prefix-)?ad(-suffix)?", meaning: match "(prefix-)ad(-suffix)", "(prefix-)ad", "ad(-suffix)" or simply "ad", on its own!
Ouch! Given that we're just interested in whether we hit a culprit or not, suddenly that whole slew of carefully recorded words meant to strengthen the regexp against false positives, doesn't! We might just as well throw them away. They of don't do any harm, of course, except wasting a bit of memory and computrons every time the regexp is used, but they don't do anything good either unfortunately.
And worse: by being there at all, as we're (particularly when working with people who are very skilled artisans at what they do) mostly tempted to assume code is there for a purpose, and one that meets the eye, unless explicitly describing the deeper magics hidden below the surface in a nearby comment, they imply being useful for something. Which wastes mind resources that try to improve on it, figuring that I'll just add this additional word that is a known ad to improve the matcher incrementally. Except here it won't achieve squat!
This is a very frequent cause of debugging-induced madness: trying to improve code that has secretly been broken for who knows how long. It's convention to write code that works, so except when in deep bug hunt mode, we read the surface of the code, rather than digging into that huge mindset which reads the entire code chunk structure, filtering all possible input through it to see what happens to it. Especially with long regexps like this.
This is something to take heed with, and a problem that grows more likely to bite you especially as expressions or nesting and complication levels rise in a chunk of code, whichever language you use. Increased complexity comes at the price of a matching decrease in readability, and before you know it, very intricate and hard to find and solve problems creep all over.
While I've given a rough suggestion of the real problem with the above regexp, I can't do any good job of going over how it should look instead, as the complete regexp lists seventeen consecutive conditions to be met, eleven of which are on/off/zero-to-many toggles and I don't know which combinations of those the regexp has been aiming for meeting in combination.
Most likely, though, picking any random one of them that satisfies the above recipe will immensely strengthen the regexp against false positives, just by giving the already provided word lists meaning again. With luck (and I'd be surprised or sad if this is not so), the Filterset.G maintainers have their regexps version controlled with good checkin comments noting what prompted every change, so they can track back to the commit where the two red culprit question marks in the regexp got added (assuming they were not there from the very beginning) to see which parts were meant to go where in the match. And if they were there from the very beginning, it's just to try mending the situation from here as best you can guess.
I believe this story has many lessons to teach about software engineering, and not only the magics of regexpcrafting. Plus, I finally found and slayed the random serial killer that would wreak havoc in the IIS family photo albums! I'm sure we will all sleep better at night now for it. Or maybe not.
(*) Technically, the regexp is a bit further constrained, by not being directly followed by ".org" and a few extensions and other known non-ads, and that it must be followed by another underscore or word character and preceded by a non-alphanumeric, =, +, % or @ character, but by and large, the words listed that make up the lion's share of the regexp, are no-ops, unless you're using it to match and parse out those chunks with them for doing some further string processing with the matches, rather than looking for a boolean "matches!" or "does not match!" result, as is the case here.
2006-08-11
IIS your server well tuned?
For fun and to scratch some web site usability itches, I have been playing with two IIS backed web sites, and while I believe my readership audience doesn't have great overlap with people who run their web sites off IIS, I hope this could be useful to someone who might end up here by way of search engine. It's two tips hoping to improve the world in the very slightest sense, offering best practices thoughts that easily bypasses IIS site developers.
But now, at least, you will!
I have been playing with using just user CSS to improve web sites, but this fallacy of random capitalization of links made my "visited" markers (a ✓ prefixed to visited links and non-breaking space characters to fill the same column for unvisited links makes for a great instant overview in vertical lists of what posts are read and not). Users of the Stylish extension might want to have a peek at the source code of my checkmark read posts user CSS, but to be really good with sites like these it probably takes a full user script to case normalize all links on the site first, which I haven't quite gotten to doing yet. I expect downcasing site internal path and query parameter names might make a perfect solution.
I have started seeing these "checkmark for read pages" appear on blogs recently, which is nice. So far I have only seen it as suffixes to links, which isn't as easy to overview in a flat list (as the right edge is rugged) as the variant with making an additional column for the visited / non-visited marking, but it's a good start. And if you don't want to meddle with unicode, you can of course employ a different background for the visited links, perhaps with a nicer still graphic of some kind. I suggest using some amount of left padding to give the image some space, rather than cluttering up the link text with the "background" imagery.
- Drop the needless X-Powered-By: ASP.NET header!
- With default settings, an IIS server running ASP.NET will happily announce this with every request for a less-than-caring web browser, not only with the HTTP standard Server header, but also via a special X-Powered-By: ASP.NET header, incurring a needless performance hit for every visitor of your site for every request, to the sole purpose of feeding the ego of some Microsoft employee, committee or other source of duhcision making. HTTP is a talkative protocol as it is, but you don't need to feed it additional payload for the sake of proving a point. Turn it off.
- URLs are case sensitive!
- I know, you don't see this much as an IIS developer, because in Microsoft land, URLs are case insensitive, and to IIS, they are too, probably to trade off worse performance of customer web sites for a lower toll on Microsoft support lines, since paths on Windows file systems have historically been case insensitive and users were expecting the same of URLs.
Anyway, the bad thing with treating URLs as were they case insensitive is that you see no visual indication of anything being wrong when you mix and match versalization of the URLs on your site as you extend it, linking to the "read post" page as /blog/readpost.aspx in one view, /Blog/ReadPost.aspx in another, and most likely also to /blog/ReadPost.aspx and /Blog/readpost.aspx through relative links from the same directory without the leading path segment. (As a visitor follows a URL to /blog/readpost.aspx and that page links adjacent posts via the ReadPost.asp capitalization, on following one, you end up at /blog/ReadPost.aspx.)
Multiply by the number of possible capitalizations offered in the query parameters, i e a random number of variants on UserID, PostID and date, for instance, and you have a huge number of different URLs that all point to the same resource (a specific post, reached through a combinatorially explosive number of same name, different case, aliases).
IIS will not care about the case discrepancy, BUT HTTP DOES.
Why? For two reasons: caching, and browser history. HTTP and your browser agree about URLs and that URLs are case sensitive. When you load /blog/readpost.aspx and /Blog/ReadPost.aspx, they are different URLs and there is no assumption of them being the same document, so there will be no attempt at pulling the second page from your browser's cache entry registered with the first page. Had the same casing been used, the second pageload would see a short 304 Not Modified response (possibly made not-as-short by the above extraneous header), without its page body payload, instantly serving the page from the browser's cache. Great! Less load on your server!
Furthermore, there is browser history. Good web sites employ style sheets (or simply do not serve any styling information at all, leaving that to browser defaults) that differentiate visually between visited links and non-visited links, typically by way of different shades of the link color. Great for usability; it's easier for your visitors to overview what content they have already read through and concentrate on the rest in their further exploration of your site. No need to read yesterday's blog posts again just because you don't recognized the title, when you will surely recall it on seeing the contents, and have wasted your time clicking the link to see it again.
This visualization also can't tell that different URLs are really the same resource, so the same blog post, linked from a view predisposed towards CamelCase, will not be recognized as the one you visited yesterday, which was linked in all lowercase, and the visual cue won't be there. So the view you came from yesterday will say you had read the post, but the view you see today won't. Browse a few posts from today's view and load the view you came through yesterday, and you will only have one post read there. It's all very confusing to your users, but IIS will make sure the pages load, and you won't see that your server draws combinatorially higher bandwidth due to the number of different ways of ending up with the same post than it would have had to, and to save face, your wesigners might just as well end up hiding the visual styling of visited and unvisited links as they just seem to break and confuse rather than help, for some weird reason nobody can quite understand.
But now, at least, you will!
I have been playing with using just user CSS to improve web sites, but this fallacy of random capitalization of links made my "visited" markers (a ✓ prefixed to visited links and non-breaking space characters to fill the same column for unvisited links makes for a great instant overview in vertical lists of what posts are read and not). Users of the Stylish extension might want to have a peek at the source code of my checkmark read posts user CSS, but to be really good with sites like these it probably takes a full user script to case normalize all links on the site first, which I haven't quite gotten to doing yet. I expect downcasing site internal path and query parameter names might make a perfect solution.
I have started seeing these "checkmark for read pages" appear on blogs recently, which is nice. So far I have only seen it as suffixes to links, which isn't as easy to overview in a flat list (as the right edge is rugged) as the variant with making an additional column for the visited / non-visited marking, but it's a good start. And if you don't want to meddle with unicode, you can of course employ a different background for the visited links, perhaps with a nicer still graphic of some kind. I suggest using some amount of left padding to give the image some space, rather than cluttering up the link text with the "background" imagery.
2006-08-02
Date/time input usability
If you have ever designed web input controls for picking a(ny) date and time, you might have been tempted to pick Blogger's approach to it, setting up a sizable array of select boxes, like this:
It works. And, as anyone who ever used them to pick a date and time different from the prepopulated one knows, it is painful to use it, even if you don't resort to the click mayhem of doing it keyboard unaidedly. That's six times two clicks plus two or three click+drags to scroll among the options of the larger select boxes plus all the precision mouse manouvering involved with hitting the very small target zones for each and every one of those clicks. Try it with a laptop mouse pad if you find it too easy with a mouse and your many years worth of computing experience. It's just not fun any more. Add the joys of converting 24 hour time to AM/PM if your brain isn't wired to twelve hour time for another optional tinge of discomfort.
What I'm trying to say is that it is not a very friendly approach to achieving the wanted functionality, though it admittedly makes it difficult (but not impossible!) to enter illegal date/time combinations. So, how would one improve upon the situation without sacrificing that criterion? After all, replacing these select boxes with a pre-populated text input reading a default date, say on the format "YYYY-MM-DD hh:mm" (annotated as such), might do away with the click mayhem involved in picking a date and time combination of your own, but it instead becomes easy to make a mistake that would require another iteration of editing, in case that date somehow turned out not quite up to specs. Especially as that format is quite likely not how the user would intuitively phrase a timestamp in writing. Another server roundtrip (for a non-ajax typical implementation) for an "uhm, try again with the date, please?" also does not equal usage bliss.
But the text entry is a great place to start, and for some use cases much better than would a popup calendar date picker be, for instance.
Aside from the specifics of this (short of perfect) visual packaging, try on this Blogger free-form date field user script (direct install link) and head over to your Blogger post editor, where you will now encounter a variant, which leaves the fields to show which date has been picked and lets you type dates by hand in a text field next to the dropdowns, updating the rest of the fields with the data it successfully understood.
While mostly crafted for my needs of half a year ago, when I was importing a lot of blog posts from an external source that listed dates formatted in a textual style I'd want to just paste and be done with, I took some time to make it a bit more useful, understanding lots of partial and complete date formats, in English, French and Swedish (I don't do too well with other languages). It is rather easy to extend it to others, as long as there is no overlap in the names or short forms of months and the relative dates "today" and "yesterday" among the languages listed.
Note how it clues you in to which parts of the date "took" by tinting the appropriate fields greenish. As the Blogger date fields only suggests a few recent years in the year dropdown, I spiced it up to liberally add whichever year you type in yourself, too, after a slight delay, in case it was a typo just as quickly fixed as it was typed. I don't recall the exact details around why I found that safeguard useful any more, but left it in place, in case there was some good thinking behind it. There often is, but I didn't seem to clue in a good enough documentation trail. Anyway, a sample of date and time formats it can handle to play with, to get you started:
Enjoy!
It works. And, as anyone who ever used them to pick a date and time different from the prepopulated one knows, it is painful to use it, even if you don't resort to the click mayhem of doing it keyboard unaidedly. That's six times two clicks plus two or three click+drags to scroll among the options of the larger select boxes plus all the precision mouse manouvering involved with hitting the very small target zones for each and every one of those clicks. Try it with a laptop mouse pad if you find it too easy with a mouse and your many years worth of computing experience. It's just not fun any more. Add the joys of converting 24 hour time to AM/PM if your brain isn't wired to twelve hour time for another optional tinge of discomfort.
What I'm trying to say is that it is not a very friendly approach to achieving the wanted functionality, though it admittedly makes it difficult (but not impossible!) to enter illegal date/time combinations. So, how would one improve upon the situation without sacrificing that criterion? After all, replacing these select boxes with a pre-populated text input reading a default date, say on the format "YYYY-MM-DD hh:mm" (annotated as such), might do away with the click mayhem involved in picking a date and time combination of your own, but it instead becomes easy to make a mistake that would require another iteration of editing, in case that date somehow turned out not quite up to specs. Especially as that format is quite likely not how the user would intuitively phrase a timestamp in writing. Another server roundtrip (for a non-ajax typical implementation) for an "uhm, try again with the date, please?" also does not equal usage bliss.
But the text entry is a great place to start, and for some use cases much better than would a popup calendar date picker be, for instance.
Aside from the specifics of this (short of perfect) visual packaging, try on this Blogger free-form date field user script (direct install link) and head over to your Blogger post editor, where you will now encounter a variant, which leaves the fields to show which date has been picked and lets you type dates by hand in a text field next to the dropdowns, updating the rest of the fields with the data it successfully understood.
While mostly crafted for my needs of half a year ago, when I was importing a lot of blog posts from an external source that listed dates formatted in a textual style I'd want to just paste and be done with, I took some time to make it a bit more useful, understanding lots of partial and complete date formats, in English, French and Swedish (I don't do too well with other languages). It is rather easy to extend it to others, as long as there is no overlap in the names or short forms of months and the relative dates "today" and "yesterday" among the languages listed.
Note how it clues you in to which parts of the date "took" by tinting the appropriate fields greenish. As the Blogger date fields only suggests a few recent years in the year dropdown, I spiced it up to liberally add whichever year you type in yourself, too, after a slight delay, in case it was a typo just as quickly fixed as it was typed. I don't recall the exact details around why I found that safeguard useful any more, but left it in place, in case there was some good thinking behind it. There often is, but I didn't seem to clue in a good enough documentation trail. Anyway, a sample of date and time formats it can handle to play with, to get you started:
1972-04-23
18:05
12/25/2005 (read commentary below if you want D/M/Y dates!)
2006-08-02 14:56
6 Aug, 1996, 04:28
samedi 28 février 2004 19:55 (irrelevant junk around ignored)
Yesterday, 12:31
aujourd'hui
igår
Enjoy!
2006-08-01
Unicode code point bookmarklet
This bookmarklet is for all of you who want to look up the unicode code point for some character you have encountered, or, the other way around, when you have a unicode code point you want the unicode character for.
I fairly often (at least several times per year, sometimes month) find myself in this situation, for some reason or other. Most of the time, it's that I never learned how to convince keyboards to deliver a particular character ("×", for instance), but took my time memorizing its code point, so I'd be able to just type it into my Emacs by typing Control-Q followed by its (octal) character code (327), regardless of whether I was at home, in Sweden, France, San Francisco, on a macintosh, unix or windows machine, or a VT100 terminal, or... ...yes, enough already; they get the point. And occasionally, it's some piece of random Unicode trivia that for some reason stuck, like that the roman numerals start at U+21B0. (Beg your pardon if I poisoned your mind there.)
Anyway, browser bookmarks are about as good and trusty as Emacsen, even if you sometimes have to look them up when in an unfriendly environment (unless you're already using Google browser sync or similar friendly tools to bring your browser environment with you wherever you go). The above bookmarklet is crafted to integrate nicely with Firefox's bookmark keywords, so you can stash it away somewhere deep in the bookmarks hierarchy to get lost in peace. Assuming you gave the bookmark the keyword "char", type "char 64" into your address bar when, say, you forgot where they hid the @ sign in the Swedish macintosh locale, and thus produce the wanted character anyway via a trip over the clipboard. I love the clipboard. (Just clicking the bookmarklet, or invoking it without a parameter, will ask for the character or character code instead.)
Just typing a number verbatim treats it as decimal, prefix it with a zero to mark it as octal (0327 for the multiplication sign), or 0x or U+ for hexadecimal, as in 0x216B for the roman numeral twelve, Ⅻ (yes, U+2160 isn't zero but Ⅰ, since the good Romans didn't feel much need for any zeroes).
And, of course, pasting the one-off 愛 猫 ♀ ❤ useful character into it gives you the brain bugs that prove oh, so useful when you're in a poor input locale with a mindful of numbers that hog your brain. I'm sure it happens all the time!
I fairly often (at least several times per year, sometimes month) find myself in this situation, for some reason or other. Most of the time, it's that I never learned how to convince keyboards to deliver a particular character ("×", for instance), but took my time memorizing its code point, so I'd be able to just type it into my Emacs by typing Control-Q followed by its (octal) character code (327), regardless of whether I was at home, in Sweden, France, San Francisco, on a macintosh, unix or windows machine, or a VT100 terminal, or... ...yes, enough already; they get the point. And occasionally, it's some piece of random Unicode trivia that for some reason stuck, like that the roman numerals start at U+21B0. (Beg your pardon if I poisoned your mind there.)
Anyway, browser bookmarks are about as good and trusty as Emacsen, even if you sometimes have to look them up when in an unfriendly environment (unless you're already using Google browser sync or similar friendly tools to bring your browser environment with you wherever you go). The above bookmarklet is crafted to integrate nicely with Firefox's bookmark keywords, so you can stash it away somewhere deep in the bookmarks hierarchy to get lost in peace. Assuming you gave the bookmark the keyword "char", type "char 64" into your address bar when, say, you forgot where they hid the @ sign in the Swedish macintosh locale, and thus produce the wanted character anyway via a trip over the clipboard. I love the clipboard. (Just clicking the bookmarklet, or invoking it without a parameter, will ask for the character or character code instead.)
Just typing a number verbatim treats it as decimal, prefix it with a zero to mark it as octal (0327 for the multiplication sign), or 0x or U+ for hexadecimal, as in 0x216B for the roman numeral twelve, Ⅻ (yes, U+2160 isn't zero but Ⅰ, since the good Romans didn't feel much need for any zeroes).
And, of course, pasting the one-off 愛 猫 ♀ ❤ useful character into it gives you the brain bugs that prove oh, so useful when you're in a poor input locale with a mindful of numbers that hog your brain. I'm sure it happens all the time!
2006-07-21
A peek at Yahoo! UI
It's been a while since I touched blog template code, and this being my place of random hackery for the various libraries and tools I stumble upon, when not in a user script domain, additional more or less useless features were added. (I fully blame Henrik for spurring me to get that pensive mood picture less randomly floating about in the air, and get this hackery started in the first place. :-)
Anyway, I have for the longest time been meaning to take a closer peek at the Yahoo! UI toolkit to see how it measures up against MochiKit, Dojo, jQuery and friends, and today ended up being that day. Long story short -- clicking my blog header above yields the hinted at useless featuritis. The rest of this article is mostly phrased as a shootout between MochiKit and YUI, as the level of maturity of these libraries match one another well, though the communities and overall design makeup do not. Hopefully some of the right people may also read it as constructive criticism on aspects to improve upon, and how.
First, though, before trying out YUI, I had a slight peek at the jQuery 1.0 alpha release, after taking note of its new
Figuring I had already used up my query credits on the jQuery list some month ago for getting my zipped-in commenter pictures, I did not ask about how it was supposed to be done to work, but moved on to YUI instead. Where jQuery has more or less the look and feel of bringing Ruby to the world of Javascript, YUI is the library that puts back the Java in Javascript, both in the good and the bad way. Good, in being a (rather consistently) high quality and extensive library, bad, in giving unwieldingly long names for the smallest of tasks. (Yes, this is a purely emotional subject. Bear with me, or skip the next two paragraphs.)
On this latter aspect, YUI is the antithesis of both jQuery and MochiKit, despite the fact that MochiKit too has broken up namespace into dot-separated modules. First and foremost because, while MochiKit too offers the benefit of only reserving one single intrusion into your variable and function namespace (the MochiKit module itself), it also lets you import the whole slew of Pythonesque / functional programming core components of MochiKit.Base into your global namespace for all sorts of really useful constructs (do try them out in the live MochiKit interpreter). While this is in part unfair comparison (as YUI does not extend the base language but rather offers tool modules and widgets) the pragmatic approach to naming and designing APIs in MochiKit is in the memorable and readable camp, whereas YUI always is in the bulky Javaesque carpal tunnel syndrome camp.
The ideal example, which is not unfair, is how both libraries abstract event handler signalling, into connecting events with a callback that gets the event passed as the first parameter, regardless of browser. By MochiKit's design, your callback gets a well documented MochiKit event object with functions like src() to see the node you had registered the handler for, target() to see which node triggered the event (sometimes a child of src) and stop(), for calling stopPropagation() and preventDefault() for the event, whereas in YUI, you get the native event object and abstract away browser differences for everything in it by calling YAHOO.util.Event.stopEvent( e ), passing along the event object.
While you should never need to see the actual native event object in a well wrapped library, MochiKit lets you do it for the rare case where you have to or want to with an event() method on its event object. Needless to say, the MochiKit approach makes it much easy on the developer to use the library's helpful abstraction that protects you from the random differences of browser implementation peculiarities with its approach, where YUI, while probably boasting the same set of abstractions, achieves it with a method that isn't as easy to pick up or use, and will most likely have developers continue to peek through the raw event object unaidedly, making their YUI applications work on their browser of choice while failing mysteriously with other browsers or platforms, even where supported by YUI. Unfortunate.
Next comes documentation. YUI, as MochiKit, has neat and tidy autodocs for everything and both ships with these in the zip file and publishes them online. It's somewhat easier to find your way around the MochiKit docs who offer a shared root node of the library tree, but it's at most an insignificant shortcoming of YUI's compared to the next issue: almost nowhere are there any visual examples at all of how YUI works in practice. The Animation module, for instance, is fairly well documented and walkthrough:ed,but nowhere online do you get any preview of how the code actually performs in reality. Edit: There actually are examples, and on the site too; they are just very well hidden (I still haven't found the actual links myself, but Google has). No easy checking of whether it actually does work across multiple browsers, if you have any, no quick peeks of actual code you can see does what you are looking for, no DIY without first reading through the tutorials or autodocs scanning for dependencies and exact call signatures.
For that, you have to download the library, unzip it, browse through a deep directory structure, find the right index files in the examples directory or scour the web to come up with good hands-on examples. YUI spread would benefit a lot from an online examples section such as MochiKit's.
Another great feature worth borrowing from jQuery is having the latest version (and why not past releases) of the unzipped source code on a permalink online, for instant peeking at the code and playing online -- and even using it from there, for the convenience and instantly up and running code without trafficking your web server or hotel. Given that The YUI libraries already by default access some CSS and images from Akamai for some of its libraries, it's beyond me why not all of the code is permalinked there, too. These are some rather easy ways of chipping off barriers to entry thresholds.
All in all, though, once you are up and running with YUI, have invented your own shortcuts there will probably never be any consensus about for the too long module names, there is very much to be glad about, in how tedium is replaced with really powerful and well thought out structures for how to shape event flows, animation and the many other things you easily end up deeply frustrated about when using Plain Old Javascript; you can smell much developer love and experience in YUI, behind the Javaisms smoke screen.
Anyway, I have for the longest time been meaning to take a closer peek at the Yahoo! UI toolkit to see how it measures up against MochiKit, Dojo, jQuery and friends, and today ended up being that day. Long story short -- clicking my blog header above yields the hinted at useless featuritis. The rest of this article is mostly phrased as a shootout between MochiKit and YUI, as the level of maturity of these libraries match one another well, though the communities and overall design makeup do not. Hopefully some of the right people may also read it as constructive criticism on aspects to improve upon, and how.
First, though, before trying out YUI, I had a slight peek at the jQuery 1.0 alpha release, after taking note of its new
$( cssSelector ).animate( properties, speed ) method. It seemed neat -- list one up to a handful of camelCased CSS properties and their wanted target values, suggest a speed in seconds, and jQuery does the animation smoothly for you. This worked well enough in the basic case of animating one element and some properties on it, but when I tried to both change the height of one div and the vertical padding of another at the same time via two consecutive calls, they ended up chained after one another in time instead. Ouch.Figuring I had already used up my query credits on the jQuery list some month ago for getting my zipped-in commenter pictures, I did not ask about how it was supposed to be done to work, but moved on to YUI instead. Where jQuery has more or less the look and feel of bringing Ruby to the world of Javascript, YUI is the library that puts back the Java in Javascript, both in the good and the bad way. Good, in being a (rather consistently) high quality and extensive library, bad, in giving unwieldingly long names for the smallest of tasks. (Yes, this is a purely emotional subject. Bear with me, or skip the next two paragraphs.)
On this latter aspect, YUI is the antithesis of both jQuery and MochiKit, despite the fact that MochiKit too has broken up namespace into dot-separated modules. First and foremost because, while MochiKit too offers the benefit of only reserving one single intrusion into your variable and function namespace (the MochiKit module itself), it also lets you import the whole slew of Pythonesque / functional programming core components of MochiKit.Base into your global namespace for all sorts of really useful constructs (do try them out in the live MochiKit interpreter). While this is in part unfair comparison (as YUI does not extend the base language but rather offers tool modules and widgets) the pragmatic approach to naming and designing APIs in MochiKit is in the memorable and readable camp, whereas YUI always is in the bulky Javaesque carpal tunnel syndrome camp.
The ideal example, which is not unfair, is how both libraries abstract event handler signalling, into connecting events with a callback that gets the event passed as the first parameter, regardless of browser. By MochiKit's design, your callback gets a well documented MochiKit event object with functions like src() to see the node you had registered the handler for, target() to see which node triggered the event (sometimes a child of src) and stop(), for calling stopPropagation() and preventDefault() for the event, whereas in YUI, you get the native event object and abstract away browser differences for everything in it by calling YAHOO.util.Event.stopEvent( e ), passing along the event object.
While you should never need to see the actual native event object in a well wrapped library, MochiKit lets you do it for the rare case where you have to or want to with an event() method on its event object. Needless to say, the MochiKit approach makes it much easy on the developer to use the library's helpful abstraction that protects you from the random differences of browser implementation peculiarities with its approach, where YUI, while probably boasting the same set of abstractions, achieves it with a method that isn't as easy to pick up or use, and will most likely have developers continue to peek through the raw event object unaidedly, making their YUI applications work on their browser of choice while failing mysteriously with other browsers or platforms, even where supported by YUI. Unfortunate.
Next comes documentation. YUI, as MochiKit, has neat and tidy autodocs for everything and both ships with these in the zip file and publishes them online. It's somewhat easier to find your way around the MochiKit docs who offer a shared root node of the library tree, but it's at most an insignificant shortcoming of YUI's compared to the next issue: almost nowhere are there any visual examples at all of how YUI works in practice. The Animation module, for instance, is fairly well documented and walkthrough:ed,
For that, you have to download the library, unzip it, browse through a deep directory structure, find the right index files in the examples directory or scour the web to come up with good hands-on examples. YUI spread would benefit a lot from an online examples section such as MochiKit's.
Another great feature worth borrowing from jQuery is having the latest version (and why not past releases) of the unzipped source code on a permalink online, for instant peeking at the code and playing online -- and even using it from there, for the convenience and instantly up and running code without trafficking your web server or hotel. Given that The YUI libraries already by default access some CSS and images from Akamai for some of its libraries, it's beyond me why not all of the code is permalinked there, too. These are some rather easy ways of chipping off barriers to entry thresholds.
All in all, though, once you are up and running with YUI, have invented your own shortcuts there will probably never be any consensus about for the too long module names, there is very much to be glad about, in how tedium is replaced with really powerful and well thought out structures for how to shape event flows, animation and the many other things you easily end up deeply frustrated about when using Plain Old Javascript; you can smell much developer love and experience in YUI, behind the Javaisms smoke screen.
2006-07-20
Google × Dilbert mashup
 As I was lazily browsing around userscripts.org this afternoon, I stumbled upon this most amusing Google × Dilbert mashup by Raj Mohan.
As I was lazily browsing around userscripts.org this afternoon, I stumbled upon this most amusing Google × Dilbert mashup by Raj Mohan.Despite being a trade-off between amusement factor and additional clutter, I opted to install it right away, especially as I rarely ever visit the Google homepage these days anyway, with my home browser equipped with the Google toolbar. That fact also made me realize that when I did visit, it was mildly annoying that it was so hard to get strips into context (long arc strips being more the rule than the exception with Dilbert). I figured I would prefer being able to flick back and forth a bit, and as I made a script like that recently for more conveniently browsing Sinfest (userscript.org page), I thought I'd do something similar for this Dilbert hack, but with a bit of ajax for doing it in-place instead of with links, as I did with Sinfest. I'm rather satisfied with the result (direct install link).
Both hacks show the previous / next strip when clicking the left / right portion of the comic. This is, I would deem, the second most intuitive behaviour for any comic browser or image album interface, the most intuitive being just "click anywhere in the image to see the next image". Which is not as useful, though, and as you can see the URLs in your status field as you hover the image and as this script targets the web savvy crowd familiar with user scripts anyway, usability won over discoverability by a comfy margin and I picked the prev/next navigation mode.
I'd like to draw some attention to the fact that while it would have been easier to just add a click event listener to the image, peeking at the coordinates of the click and deciding whether it was in the left or right portion of the image, I went through the trouble of setting up an image map for achieving the effect of "hover to see what will happen on clicking", as we are used to from ages of browser handling experience.
Also, and this is the part where many ajax happy developers foul out, it makes these links behave as links in all respects, allowing those who want to open them in a new tab or window to do so, in the same way they have their browser configured to do it. Shift click, middle click, right-click-and-pick-an-option-in-the-menu, et cetera. You can't do that if you barge on adding event handlers that just do it your way.
Back to the Dilbert hack. As most of the Dilbert strips are three-pane rather than four-pane, as in the case of Sinfest, it struck me it would look neater still having the clickable surface split in three, as that would also allow for a link to the strip itself in the middle. (A bit difficult to share links with others to a strip you liked, if the URL you found it at was http://www.google.com/, see. Most people would probably not understand which particular strip you were referring to, but think you were being obnoxious.) And it seems to work quite well, too.
Enjoy!
2006-07-18
Spam fighting phpBB boards
The FireBug forums were rather heavily spam infested recently. Most of it was fortunately in the rather boring General section, but it had spilled into a few of the other categories too, so I asked Joe Hewitt if I could help out blasting it to bits (for the benefit of the community -- it's a small service to offer for a project you really care about), on those occasions I peer through the forums anyway. I could.
Fighting spam on a phpBB board is painful, as it's probably about as much work getting rid of it as getting it there in the first place (for the spammers); lots of clicking and waiting for page loads and the like. I had anticipated this lack of convenience, though, and was prepared to rewrite the phpBB admin interface to make it more workable.
 Thus the phpBB quick purging (direct install link) user script was born. If you have logged in with admin rights (the script knows, by the presence of the link "you can moderate this forum"), it adds delete links to all posts or threads in view, and a "delete all" link at the bottom. Enjoy!
Thus the phpBB quick purging (direct install link) user script was born. If you have logged in with admin rights (the script knows, by the presence of the link "you can moderate this forum"), it adds delete links to all posts or threads in view, and a "delete all" link at the bottom. Enjoy!
Fighting spam on a phpBB board is painful, as it's probably about as much work getting rid of it as getting it there in the first place (for the spammers); lots of clicking and waiting for page loads and the like. I had anticipated this lack of convenience, though, and was prepared to rewrite the phpBB admin interface to make it more workable.
Thus the phpBB quick purging (direct install link) user script was born. If you have logged in with admin rights (the script knows, by the presence of the link "you can moderate this forum"), it adds delete links to all posts or threads in view, and a "delete all" link at the bottom. Enjoy!